2020. 4. 9. 17:37ㆍIT/AWS
1. 설명
Redshift는 클라우드 데이터 웨어하우스이다. 데이터 작업을 빠르고 간단하게 수행하고, AWS 에코시스템에 손쉽게 연결할 수 있도록 한다.
Redshift를 사용하는 일반적인 프로세스는 다음과 같다.
사용할 데이터를 S3에 적재하고, Redshift에 로드하여 데이터를 분석한다.
본문에서는 샘플 데이터(미국 항공사 데이터)를 S3에 적재하고, 이를 로드하여 데이터를 분석한다.
2. Redshift 구성 및 연결
Redshift 클러스터를 구성한다. 클러스터 식별자와 노드 유형, 노드 수를 입력한다.

데이터베이스를 구성한다. 데이터베이스 이름, 마스터 계정 이름 및 비밀번호를 입력한다.
구성할 VPC 및 보안그룹을 지정하고, 클러스터를 생성한다. 클러스터의 속성을 확인하고, 생성을 기다린다. (최대 5분 소요)

생성이 완료되면, 클라이언트에서 Redshift에 연결한다. 본문에서는 웹 기반의 PostgreSQL을 이용한다.

다음과 같이 사용자 이름, 비밀번호, 데이터베이스명, 포트를 입력하여 연결한다.
Host에는 클러스터 속성에서 확인할 수 있는 엔드포인트를 입력한다.

클러스터의 엔드포인트는 아래와 같이 확인할 수 있다. 클러스터가 available 상태여야 연결이 가능하다.

3. 데이터 로드 및 쿼리 실행
연결된 클라이언트에서 테이블을 생성하여 데이터를 삽입하거나, S3에서 COPY 명령으로 데이터를 로드할 수 있다.
S3에서 데이터로드 시, Redshift Role을 입력해야 한다.


데이터 로드 후, 다음과 같이 쿼리를 실행하여 로드된 데이터를 확인할 수 있다.

EXPLAIN 명령을 통하여 쿼리를 실행할 때, Redshift가 수행하게 되는 단계를 확인할 수 있다.
Redshift는 인덱스 사용 없이, 대량의 데이터를 빠르게 스캔한다. 아래의 경우, 몇 초 내에 9천만 행을 스캔한다.

ANALYZE 명령을 통하여 원하는 테이블에 저장된 데이터를 분석할 수 있다.
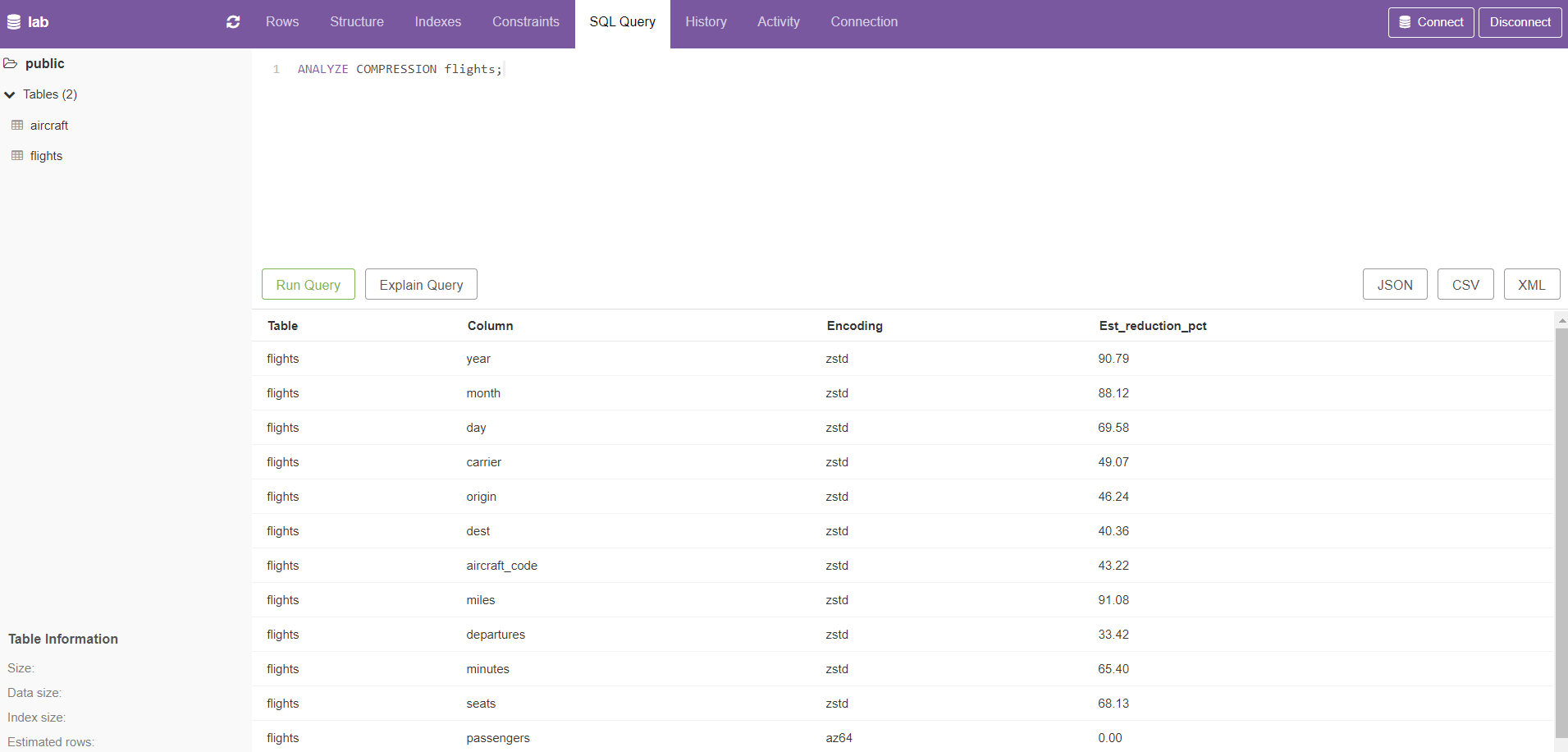
로드한 테이블들이 차지하는 용량을 확인한다.

4. 결과 확인
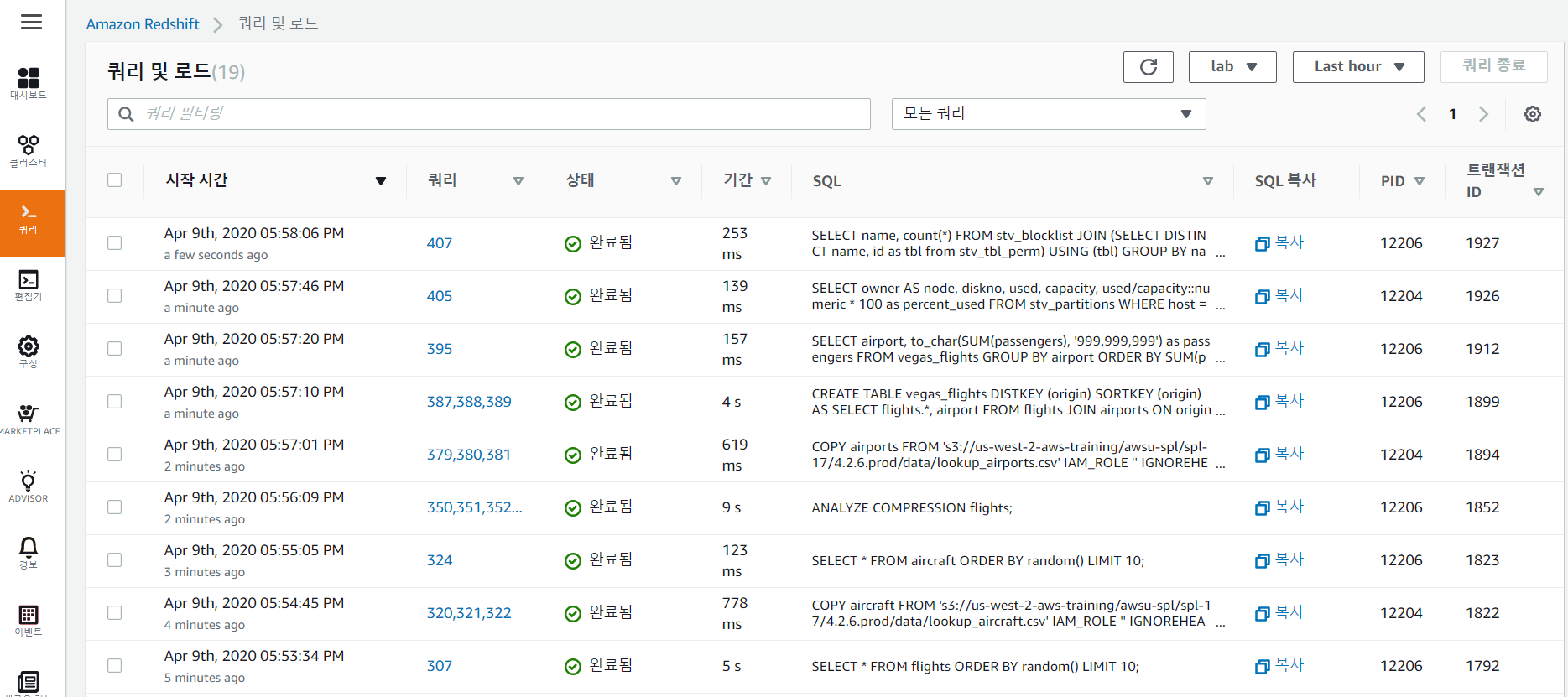
위와 같이 SQL를 통하여 Redshift를 이용하였다. AWS 콘솔 상에서 쿼리와 관련된 모니터링을 확인할 수 있다.
다음과 같이 쿼리 기간, 쿼리를 실행한 사용자, SQL문을 확인할 수 있다.
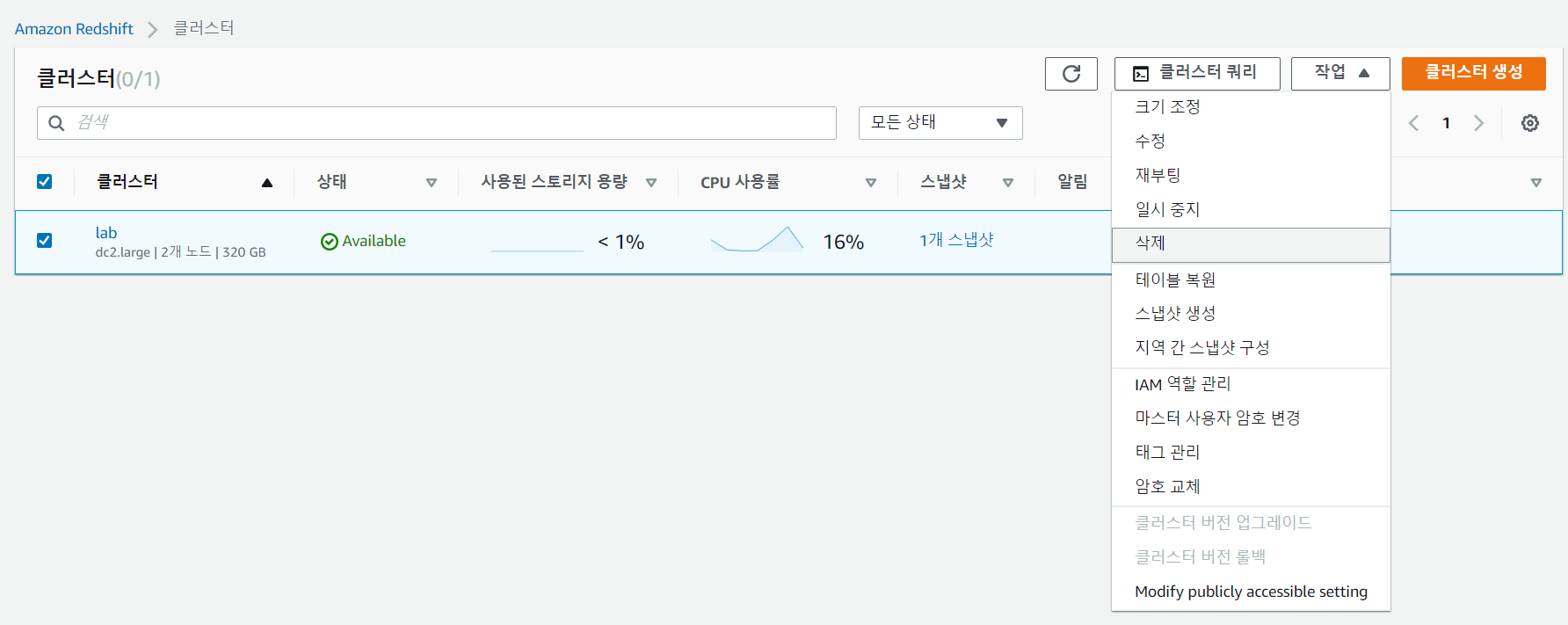
원하는 데이터 작업 후, 클러스터를 중지하거나 삭제한다.
'IT > AWS' 카테고리의 다른 글
| Amazon Kinesis Data Streams, Kinesis Data Firehose 이용하여 로그 데이터 수집/저장 (0) | 2020.05.04 |
|---|---|
| AWS Storage gateway를 이용한 EFS와 S3 간 데이터 전송 (0) | 2020.04.23 |
| AWS Lambda 기반의 공공데이터 호출 및 변환 (0) | 2020.04.09 |
| AWS EC2 재부팅 시, 사용자 데이터(User Data) 적용 (0) | 2020.04.09 |
| AWS API Gateway를 이용한 DynamoDB 데이터 적재 (0) | 2020.04.09 |