2020. 4. 9. 11:37ㆍIT/AWS
1. 설명
공공데이터포털(https://www.data.go.kr/)에서 API를 이용해 날씨 데이터를 호출하고자 한다. 해당 사이트에서 발급받은 인증키를 넣어 브라우저로 호출하면 다음과 같은 json 형식의 결과가 나온다.
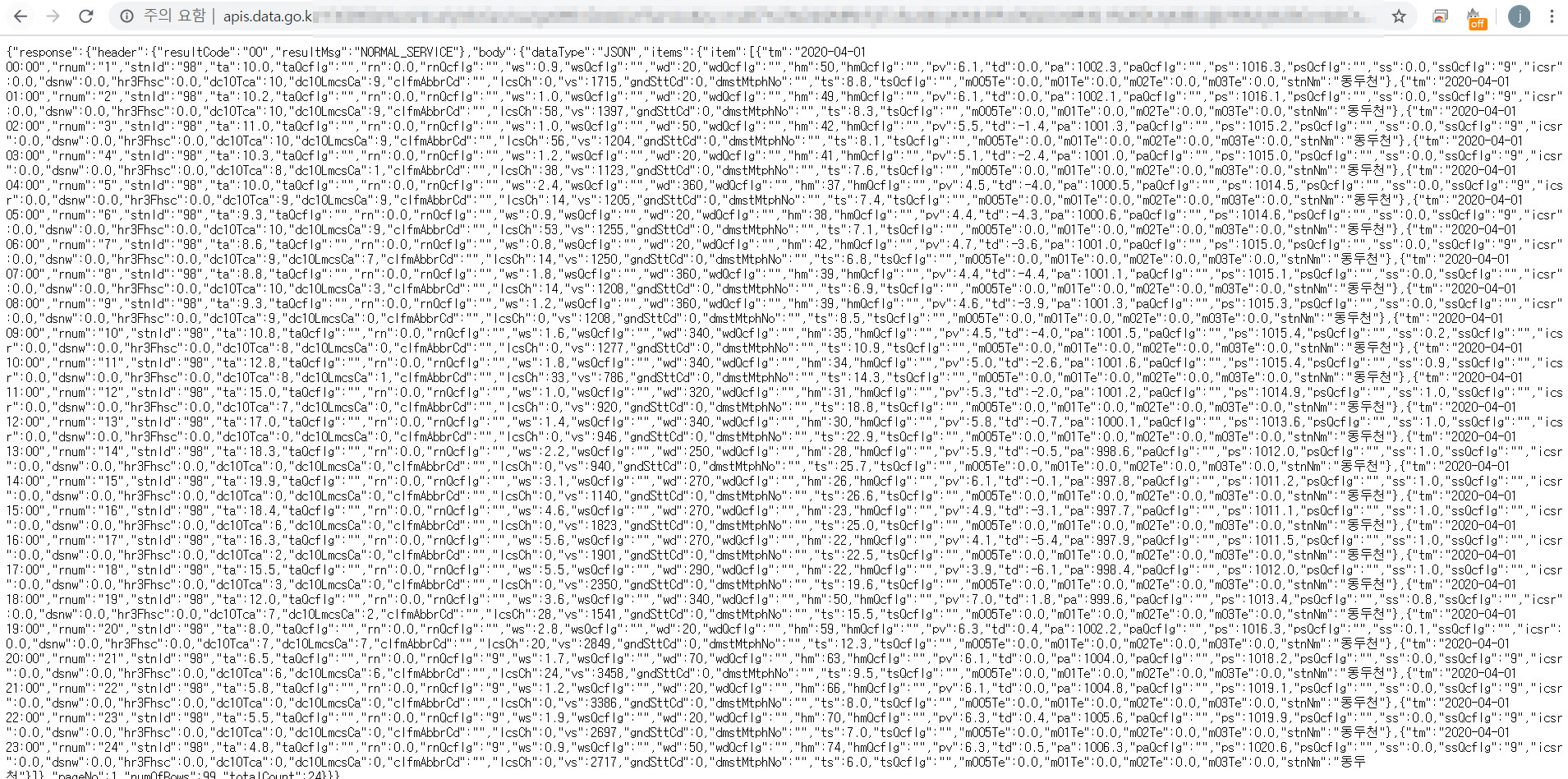
본문에서는 Lambda 함수를 이용하여 위와 같이 호출한 json 형식의 데이터를 csv 형식으로 변환하고, 이를 S3에 업로드하고자 한다.
2. 구현
Lambda Layers를 통하여 여러 함수가 공유하는 코드 또는 라이브러리 데이터를 관리할 수 있다.
본문에서는 라이브러리를 Layer에 등록하여 사용하였지만, 한정된 Layer 용량으로 필요한 라이브러리를 모두 등록할 수 없었다. Layer에 등록하지 못한 라이브러리는 따로 zip로 형태로 Lambda_function.py와 함께 압축하여 Lambda에 업로드하여 실행하였다.
Lambda_function 파일로 작성된 코드는 다음과 같다.
import requests
import pandas as pd
import os
import datetime as dt
import matplotlib.pyplot as plt
import urllib3
import json
from pandas.io.json import json_normalize
import boto3
import sys
import csv
from dateutil.parser import parse
from datetime import date, timedelta
from logging import handlers
observatoryArrList = [90,93,95,98,99,100,101,102,104,105,106,108,112,114,115,119,121,127,129,130,131,133,135,136,137,138,140,143,146,152,155,156,159,162,165,168,169,170,172,174,177,184,185,188,189,192,201,202,203,211,212,216,217,221,226,232,235,236,238,243,244,245,247,248,251,252,253,254,255,257,258,259,260,261,262,263,264,266,268,271,272,273,276,277,278,279,281,283,284,285,288,289,294,295]
csvMetaArrList = ["date", "time", "stnId", "stnNm", "ta", "taQcflg", "hm", "hmQcflg", "ws", "wsQcflg", "rn", "rnQcflg", "dsnw"]
maxRows = 999
maxCnt = 999
today = date.today()
yesterday = date.today() - timedelta(1)
targetday = yesterday.strftime('%Y%m%d')
startDateArrList = [targetday]
endDateArrList = [targetday]
csvfiles = ("/tmp/weather_%s.csv" % targetday)
s3bucket = 'S3 버킷 이름'
s3file = ("S3 폴더 이름/weather_%s.csv" % targetday)
webhook_url = "Slack에서 발급받은 Url"
def call_weather_api(start_date, end_date):
api_key = '발급받은 API KEY'
url_format = 'http://apis.data.go.kr/1360000/AsosHourlyInfoService/getWthrDataList?ServiceKey={api_key}&numOfRows={maxRows}&pageNo=1&dataType=JSON&dataCd=ASOS&dateCd=HR&startDt={startDate}&startHh=00&endDt={endDate}&endHh=23&stnIds={snt_id}&schListCnt={maxCnt}'
headers = {'content-type': 'application/json;charset=utf-8'}
urllib3.disable_warnings()
csvData = pd.DataFrame()
for index, stnIds in enumerate(observatoryArrList):
print("=== req index: %s===" % index)
print("Start %s Weather" % start_date)
print("End %s Weather" % end_date)
print("Observatory: %s" % stnIds)
url = url_format.format(api_key=api_key, maxRows=maxRows, startDate=start_date, endDate=end_date, snt_id=stnIds, maxCnt=maxCnt)
response = requests.get(url, headers=headers, verify=False)
print("Req Status Code: %s" % response.status_code)
# check 200 OK
if response.status_code == 200:
outDate = list()
outTime = list()
resJson = response.json()
# check resultcode 00(성공) / 02(DB에러, 요청에러)/ 03(NoData)
if resJson['response']['header']['resultCode'] == "00":
print("Result Code : 성공")
resItem = json_normalize(resJson['response']['body']['items']['item'])
resultDF = pd.DataFrame(resItem)
for i in resultDF['tm']:
dt = parse(i)
outDate.append(dt.date())
outTime.append(str(dt.time()).replace(":", "")[0:2])
resultDF['date'] = outDate
resultDF['time'] = outTime
outResult = resultDF[csvMetaArrList]
csvData = pd.concat([csvData, outResult])
else:
print("Result Code : 실패 %s" % resJson['response']['header']['resultCode'])
csvData.to_csv("/tmp/weather_%s.csv" % start_date, index=False, encoding="utf-8")
csvData = csvData.reset_index(drop = True)
def put_s3(targetday):
s3 = boto3.client('s3')
s3.upload_file(csvfiles, s3bucket, s3file)
def send_slack():
content = "Files upload error"
payload = {"text": content}
requests.post(
webhook_url, data=json.dumps(payload),
headers={'Content-Type': 'application/json'}
)
def lambda_handler(event, context):
try:
i = 0
for startReqDate, endReqDate in zip(startDateArrList, endDateArrList):
print("*** call_weather_api index: %s ***" % i)
call_weather_api(startReqDate, endReqDate)
put_s3(startReqDate)
i += 1
except:
send_slack()
오늘날짜를 기준으로 어제의 날짜(targetday)를 구하고, 어제 날짜(0~24시)에 해당되는 날씨 데이터를 호출한다. 호출한 데이터는 Python Pandas 라이브러리의 Dataframe을 통하여 행과 열을 가진 형태로 변환한다. 변환된 데이터는 Lambda 실행 시, 사용할 수 있는 폴더(tmp) 아래에 weather_%s.csv 형태로 저장된다. 저장된 csv 파일은 설정해놓은 S3 경로로 업로드 된다.
다음과 같이 python 3.8 환경에서 zip형태로 파일을 업로드하여 실행한다.

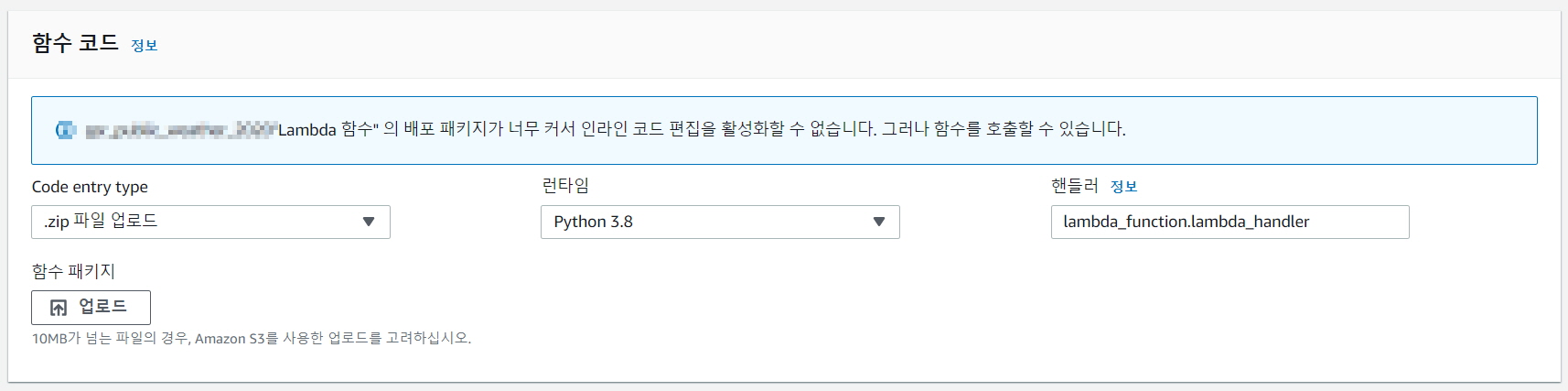
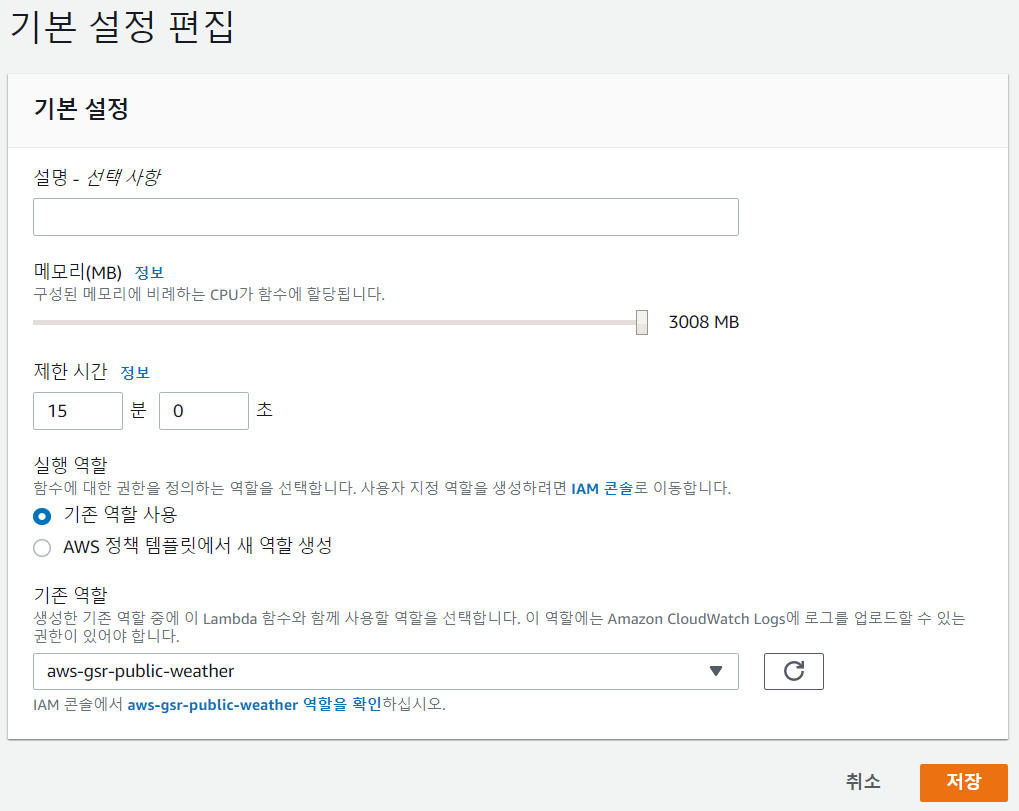
하루가 아닌 1개월, 1년치의 날씨를 호출할 경우, Lambda의 기본 실행 시간 내에 처리할 수 없었다.
다음과 같이 실행시간과 메모리를 조절하여 실행하였다.
3. 구현 결과
다음과 같이 CloudWatch Events 트리거를 통해 원하는 시간에 실행될 수 있도록 설정한다.

지정한 경로에서 실행한 시간에 파일이 저장된 것을 확인한다.

다음과 같이 저장된 파일의 내용을 확인한다.

'IT > AWS' 카테고리의 다른 글
| AWS Storage gateway를 이용한 EFS와 S3 간 데이터 전송 (0) | 2020.04.23 |
|---|---|
| Amazon Redshift 구성 및 사용 (0) | 2020.04.09 |
| AWS EC2 재부팅 시, 사용자 데이터(User Data) 적용 (0) | 2020.04.09 |
| AWS API Gateway를 이용한 DynamoDB 데이터 적재 (0) | 2020.04.09 |
| AWS DataSync 이용하여 S3 버킷에서 EFS 파일 시스템으로 데이터 전송 (0) | 2020.04.09 |